データがないときに使う:scikit-learnによるダミーデータ生成入門
Aru
Aru's テクログ(Aruaru0)

PythonでAtCoderを始めるためのチートシート第2弾です。この記事では、AtCoderを始めた人向けに、競技プログラミングでよく使う、基本的なPythonの記述方法について解説しています。目次でやりたいことを見つけて検索できる、逆引きっぽい構成にしています。活用してください。
入力のチートシートはこちらの記事を参考にしてください

その他のAtCoderに役立つ記事の一覧は以下にあります

Pythonの場合、’/‘記号で割り算をすると浮動小数点で演算が行われてしまいます。結果を整数で返したい場合は’//‘記号を使います。結果は、小数点以下の切り捨てです。
3 // 2
x // 3再帰を使ったプログラムで「プログラムは間違ってなさそうなのに、一部のテストケースでRE(Runtime Error)がでる」という場合は、スタックサイズを調整しましょう。
この現象はPythonのデフォルトの再起用のスタックサイズが小さいため発生します。
再帰用のバッファサイズが原因だった場合は、以下のコードをプログラムの先頭に入れることで解決します。
import sys
sys.setrecursionlimit(10**6)出力したい形式
1
2
3
4
5
forループで書くのが簡単です
ans = [1,2,3,4,5]
for e in ans:
print(e)以下のように書く方法もあります
ans = [1,2,3,4,5]
print(*ans, sep='\n')これまでの経験上、forで書いてギリギリ間に合わないみたいなことはなかったので、forが楽かもしれません。
出力したい形式
1 2 3 4 5
Pythonでは、この形式の出力が簡単です。forを使うよりこちらをおすすめします。変数の先頭に*をつけるだけで1行で出力してくれます。
ans = [1,2,3,4,5]
print(*ans)Pythonの場合、配列(list)の作成方法はいくつかありますが、私がおすすめする方法です。
[]の中でfor文が使えます
n = 10
a = [0 for _ in range(n)]
print(a)出力結果
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]n = 10
a = [i for i in range(n)]
print(a)出力結果
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9][n][m]個の配列を作成for文を入れ子にします
n,m = 3, 5
a = [[0 for _ in range(m)] for _ in range(n)]
print(a)出力結果
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
0が10個の配列だと、以下のような感じで配列を作れます
a = [0] * 10こちらの方法を紹介しない理由は、以下のようなパターンで問題があるからです。a[0][1]を変えたつもりなのに、3箇所変化しています(内部の0の4つの実体が同じため)。気づかずにエラーになるトラブルを防ぐため、forを使った方法で統一したほうが良いです。
a = [[0]*4]*3
print(a)
a[0][1] = 1
print(a)出力結果
[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
[[0, 1, 0, 0], [0, 1, 0, 0], [0, 1, 0, 0]]n = 10
a = [[] for _ in range(n)]
print(a)出力結果
[[], [], [], [], [], [], [], [], [], []]配列のl番目の要素からr-1番目の要素を取り出す場合は、以下のようにします。0インデックス(0始まり)なので、[1:3]と指定した場合は、2番目の文字と3番目の値が取り出されます(1,2,3番目ではなく、1,2番目なので注意)
末尾側がどこまで取り出されるのかにも注意してください(たまにミスります)
a = [1,2,3,4,5,6,7,8,9,10]
b = a[1:3]
print(b)出力結果
[2, 3]末尾まで取り出す場合は、末尾の値は省略できます
a = [1,2,3,4,5,6,7,8,9,10]
b = a[1:]
print(b)出力結果
[2, 3, 4, 5, 6, 7, 8, 9, 10]先頭から取り出す場合は、先頭の値は省略できます。また、負の値を設定することで末尾からの文字数が指定できます。
a = [1,2,3,4,5,6,7,8,9,10]
b = a[:-1]
print(b)出力結果
[1, 2, 3, 4, 5, 6, 7, 8, 9]Pythonで配列を反転させるのは簡単です
a = [1,2,3,4,5,6,7,8,9,10]
b = a[::-1]
print(b)出力結果
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]要素の数はlenで調べることができます
a = [1,2,3,4,5,6,7,8,9,10]
n = len(a)
print(n)出力結果
10リストでも同じことができますが、dequeの方が高速です。TLEが出る場合はdequeを試してみることをお勧めします。
dequeを使うには、collectionsパッケージをインポートする必要があります
from collections import dequeキューの末尾にデータを追加します
d = deque()
d.append(5)
d.append(10)
print(d)出力結果
deque([5, 10])キューの先頭にデータを追加します
d = deque()
d.appendleft(5)
d.appendleft(10)
print(d)出力結果
deque([10, 5])キューの末尾からデータを取り出します
d = deque()
d.append(10)
d.append(3)
x = d.pop()
print(x, d) 出力結果
3 deque([10])キューの先頭からデータを取り出します
d = deque()
d.append(10)
d.append(3)
x = d.popleft()
print(x, d)出力結果
10 deque([3])キューの中で値が等しいものを削除します。削除は、先頭から検索して最初に見つかった要素です。要素がない場合はエラーになります。
d = deque()
d.append(10)
d.append(3)
d.append(10)
print(d)
d.remove(10)
print(d)出力結果
deque([10, 3, 10])
deque([3, 10])要素数はリストなどと同じように、lenで調べることができます。
d = deque()
d.append(10)
d.append(3)
n = len(d)
print(n)出力結果
2文字をコードに変換する場合はordを、文字コードを文字に変換する場合はchrを使います。
print(ord('A'))
print(chr(65))出力結果
65
Aa = "abcde"
b = list(a)
print(b)出力結果
['a', 'b', 'c', 'd', 'e']a = ['a', 'b', 'c', 'd', 'e']
b = "".join(a)
print(b)出力結果
abcdea = "abcdef"
print(a.upper())
b = "ABCDEF"
print(b.lower())出力結果
ABCDEF
abcdefa = "abcdef"
b = a[::-1]
print(b)出力結果
fedcba一部を抽出するのは配列と同じです
s = "abcde"
print(s[2:4])出力結果
cdPythonの文字列はイミュータブルなため変更できません。なのでs[1] = ‘A’みたいな代入はできません。変更したい場合は、一旦リストにするのが楽です。文字列に戻すときはjoinを使います。
s = "abcde"
# リストに変換
sl = list(s)
print(sl)
# 2文字目を置換
sl[1] = 'B'
# 文字列に戻す
t = "".join(sl)
print(t)出力結果
['a', 'b', 'c', 'd', 'e']
aBcdeset型は重複を許さない集合です。2回目のadd(3)では、すでに3はあるので追加されません。
a = set()
a.add(1)
a.add(2)
a.add(3)
print(a)
a.add(3)
print(a)出力結果
{1, 2, 3}
{1, 2, 3}集合型では、和集合、積集合などの演算を行うことができます
a = set([1,2,3])
b = set([2,3,4])
print(a|b) # 和集合
print(a&b) # 積集合
print(a^b) # どちらかだけに含まれるもの出力結果
{1, 2, 3, 4}
{2, 3}
{1, 4}listからsetに変換するには以下のようにします。変換すると重複した値はまとめられます。
a = [1,2,3,4,5,6,7, 1,2,3]
b = set(a)
print(a)
print(b)出力結果
[1, 2, 3, 4, 5, 6, 7, 1, 2, 3]
{1, 2, 3, 4, 5, 6, 7}listに変換するとソートなどができるようになります。
a = set([100, 12, 3,4,6,2,1])
b = list(a)
print(a)
print(b)
b.sort()
print(b)出力結果
{1, 2, 3, 4, 100, 6, 12}
[1, 2, 3, 4, 100, 6, 12]
[1, 2, 3, 4, 6, 12, 100]辞書型です。dictとdefaultdictは似た使い方ができますが、辞書に存在しない場合の値を設定できるのでdefaultdictがおすすめです。以下では、defaultdictを使って説明します。
defaultdictを使う場合は、パッケージをインポートする必要があります。
dictは、辞書に登録されていない要素にアクセルするとエラーになります。
d = dict()
d['a'] = 10
print(d['a'])
print(d['b'])出力結果
10
Traceback (most recent call last):
File "/tmp/t.py", line 12, in <module>
print(d['b'])
KeyError: 'b'これを回避するには、以下のようなチェックを毎回行う必要があり面倒です。なのでdefaultdictを使ったほうが楽です
if 'b' in d: print(d['b'])見つからない場合に0を返す辞書は以下のように宣言します。d['b']は定義されていないので0となります。
from collections import defaultdict
d = defaultdict(int)
d['a'] = 10
print(d['a'])
print(d['b'])出力結果
10
0-1に初期化する場合は、以下のようにします。
from collections import defaultdict
d = defaultdict(lambda:-1)
d['a'] = 10
print(d['a'])
print(d['b'])出力結果
10
-1空のリストで初期化した辞書を宣言する場合は以下のようにします。
from collections import defaultdict
d = defaultdict(list)
d['a'].append(10)
d['a'].append(20)
print(d['a'])
print(d['b'])出力結果
[10, 20]
[]インデックスを複数要素にする場合は、タプルにする必要があります。タプルは超簡単に言えばリストの[]を()に変えたものです
from collections import defaultdict
d = defaultdict(int)
d[(1,'a')] = 10
print(d[(1, 'a')])出力結果
10文字列を番号に変換する辞書と、逆引き辞書を作成
a = ["test0", "test1", "test2"]
name2idx = {x:i for i, x in enumerate(a)}
print(name2idx)
idx2name = {i:x for i, x in enumerate(a)}
print(idx2name)出力結果
{'test0': 0, 'test1': 1, 'test2': 2}
{0: 'test0', 1: 'test1', 2: 'test2'}name2idxの辞書から逆引き辞書を作成する場合
idx2name = {name2idx[e] : e for e in name2idx}
print(idx2name)実行結果
{0: 'test0', 1: 'test1', 2: 'test2'}値から配列のインデックスを取り出す辞書を作成。b[要素の値]として何番目の要素(インデックス)を取り出すことが可能。
a = [1,32,4,5,7,32,23,13,14,3]
b = {v: i for i , v in enumerate(a)}
print(b)実行結果
{1: 0, 32: 5, 4: 2, 5: 3, 7: 4, 23: 6, 13: 7, 14: 8, 3: 9}このテクニックは後で説明する範囲圧縮でも使います。
再帰処理を高速化する方法として、一度演算した結果を保存しておき同じ入力に対しては、演算した結果を返す「メモ化再帰」というテクニックがあります。Pythonでは、メモ化再帰を簡単に実現することができます。
以下は、ABC340-C問題の解答サンプルです。
functoolsのcacheをインポートして、デコレーター(@マークの行)として、cacheをつけるだけで、メモ化再帰を自動で行うことができます。
下記のように記述することで、一度計算したf(N)がキャッシュされます。
キャッシュ=「一時的に保存される」と捉えればOKです
from functools import cache
@cache
def f(N) :
if N <= 1 : return 0
return N + f(N//2) + f((N+1)//2)
N = int(input())
print(f(N))デコレーターの上手い使い方だと思います
1〜$10^10$の範囲の数値を、最大要素数の数値に圧縮します。大小関係が重要な場合など、値の範囲を圧縮してもよいときに利用します。セグメントツリーなどと一緒に使うこともあります。
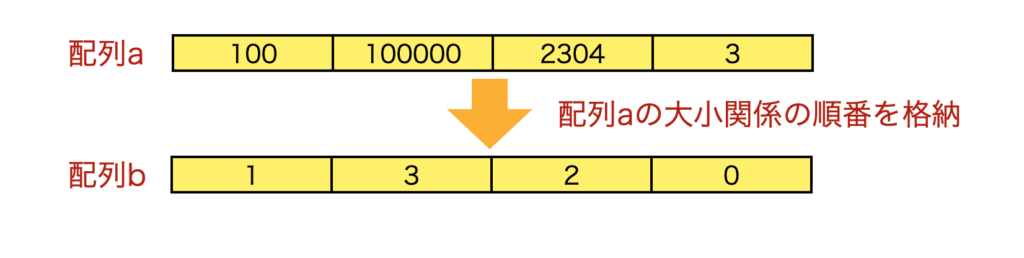
import random
a = [random.randint(1, 10**10) for _ in range(100000)]
tbl = {v:i for i, v in enumerate(list(set(a)))}
b = [tbl[e] for e in a]bの値からaの値を求める逆変換のテーブルが必要な場合は、以下のコードで作成できます。rev_tbl[b[0]]などとすることで、b[0]の値に変換することができます。
rev_tbl = {i:v for i, v in enumerate(list(set(a)))}PythonでAtcoderに参加する場合の入力以外のチートシートを作成しました。
私がPythonを使い始めて引っかかった部分を中心としていますが、参考になれば幸いです。





