
MacBook Air(M5)のディープラーニング性能を検証|PyTorch, YOLOv8, LMStudio
Aru
Aru's テクログ(Aruaru0)

本記事では、サイバーエージェントが開発したCALM2を使用してチャットボットを作成する方法を詳細に解説します。また、CALM2のトークナイザーが最大32,000トークンにも関わらず日本語では50,000文字相当の入力が可能という点にが気になったので、実際にどのようにトークン化されるかも調査しました。

CALM2(CyberAgentLM2)はサイバーエージェントが開発した大規模言語モデル(LLM)です。日本語に特化した大規模言語モデルという部分が特徴です。
他の記事にも書きましたが、「最大32,000トークンまでの入力に対応していて日本語の文章として約50,000文字を一度に処理する」ことができます。
実はCALM2については、他の記事でも動かしたことがあります。今回は、そちらの記事よりも少し深掘りをしてみました。

また、CALM2+RAGというパターンも試しています。こちらについては以下を参照してください。

最大32,000トークンで、約50,000文字ということでトークンがどのように区切られているのか気になったので調査してみました。
トークンの分割とは、入力された文章を、一定のルールでトークンに分割するという処理です。
以下はOpenAIのGPT-3.5のトークナイザーによる分割の結果です。
OpenAIのGPT-3.5のトークナイザー(https://platform.openai.com/tokenizer)で分割をチェックすると以下のようになりました。
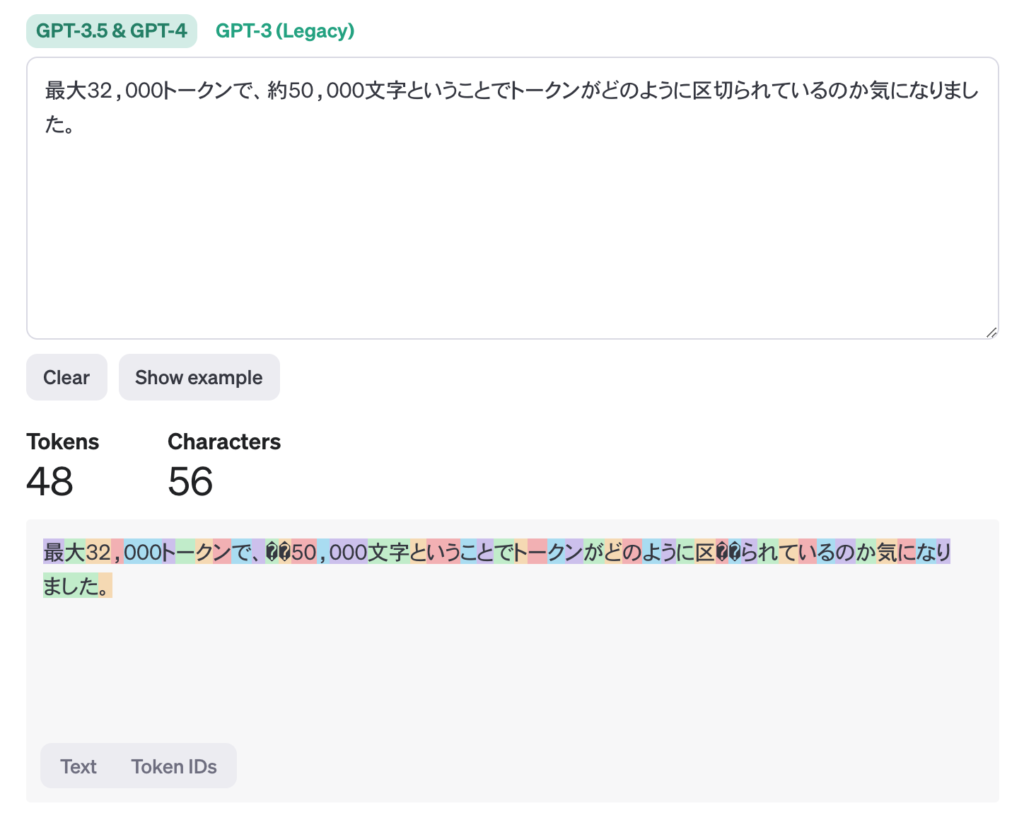
CPT-3.5では、日本語の文章を入力すると「ほぼ1文字単位」でトークン化されています。
上記の例では、56文字が48トークンに変換されていますので、$56/48\approx 1.17$文字/トークンとなります。
CALM2は、32,000トークンで50,000文字なので、、単純計算で平均1.56文字/トークンになります。GPT-3.5と比較して効率よくトークン化できていることになります。
以下、CALM2では、日本語文書がどのようにトークン化されるのかを実際にチェックしてみました。

ちなみに、英語の場合は、大体の場合、単語単位でトークン化されます。1文字1トークンと比較すると長い文章が入力できることになります。

トークンの特徴ベクトルに変換する部分でも有利な気がしますね。
ユーザが入力してLLMが回答、再びユーザが入力してLLMが回答というチャットの場合のLLMへの入力も気になる点の1つです。
CALM2の公開されているテンプレートでは、以下のように入力することになっています。
公開されているチャットのテンプレート
USER: {user_message1}
ASSISTANT: {assistant_message1}<|endoftext|>
USER: {user_message2}
ASSISTANT: {assistant_message2}<|endoftext|>
USER: {user_message3}
ASSISTANT: {assistant_message3}<|endoftext|>これを見ると、これまでの会話を1つのプロンプトにまとめて入力するように見えます。実際にLLMでは、これまでの会話を1つのプロンプトにまとめて入力する必要がありますが、これも確認しています。
これまでに説明した二点について実際にプログラムを組んで確認してみました。
確認は、Google Colabで行いました。ランタイプはT4 GPUで動作します。
必要なライブラリをインストールします。以下のコマンドをコードセルで実行します。
!pip install -q accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7トークナイザーとモデルを初期化します。今回利用したのはチャット用のcyberagent/calm2-7b-chatです。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model = AutoModelForCausalLM.from_pretrained("cyberagent/calm2-7b-chat",
device_map="auto",
torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("cyberagent/calm2-7b-chat")
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
model.eval()※ダウンロードに時間がかかるのでしばらく待ちます
とりあえず、GPT-3.5と同じ文字列をトークナイザーで変換してみます。
prompt = "最大32,000トークンで、約50,000文字ということでトークンがどのように区切られているのか気になりました。"
input_ids = tokenizer(prompt, return_tensors="pt")#, max_length=32, padding=True, truncation=True)
for e in input_ids['input_ids'][0]:
r = tokenizer.decode(e)
print(r, end=" | ")
print(f"\n文字数={len(prompt)}, トークン数={len(input_ids['input_ids'][0])}")実行結果は以下になります。結果を見ると、「もじ」「どのように」などのように、ある程度の意味のある塊でトークンに分割されているように見えます。ただ、「トーク」「ンで」みたいな分割もあるので、きっちり形態素解析されているわけではなさそうです。
トークン化の手法にあまり詳しくないですが、BPE(Byte Pair Encoding, バイトペア・エンコーディング )みたいなエンコーディングになっている感じがします。
最大 | 3 | 2 | , | 0 | 0 | 0 | トーク | ンで | 、 | 約 | 5 | 0 | , | 0 | 0 | 0 | 文字 | という | ことで | トーク | ンが | どのように | 区 | 切 | られている | のか | 気になり | ました | 。 |
文字数=56, トークン数=30文字数56文字に対して30トークンなので、$56/30\approx 1.87$文字/トークンと、GPT3.5と比べてかなり少ないトークン数に変換していることがわかります。
一度に入力できるトークン数が決まっているので、文字数に対してトークン数が少なくなれば、それだけ長い文章を一度に入力できることになります。これが、32,000トークンで50,000文字理由です
このようにCALM2では、日本語のトークン化をかなり効率よく行えているようです。
以下、プロンプトにこれまでの会話を含めないとどうなるかを確認するために、①「これまでの会話をプロンプトに含めないもの」と、②「これまでの会話をプロンプトに含めるもの」の2つを作成して実験してみました。
チャットを作る時のうまく動作しない実装例です。
入力文字列のみでpromptを生成し、トークナイザーとモデルに入力して回答を生成しています。
なお、このプログラムではstreamerを設定しています。下記プログラムのように、streamer=を設定するとアシスタントの出力をChatGPTのような感じで段階的に結果が出力されるようになります。
while True :
txt = input("入力: ")
if txt == "quit" : break
prompt = f"""USER:{txt}
ASSISTANT:"""
input_ids = tokenizer.encode(prompt, return_tensors="pt")
print("アシスタント:", end=" ")
with torch.no_grad():
tokens = model.generate(
input_ids = input_ids.to(model.device),
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k = 50,
streamer=streamer,
)以下は、チャットの結果です(「入力:」がユーザー側の入力です)
入力: これから日本について質問します。よろしいですか?
アシスタント: はい、もちろんです。どんな質問でもお気軽にお聞きください。
入力: 一番高い山は?
アシスタント: 一番高い山はエベレストです。
入力: 二番目に高い山は?
アシスタント: 二番目に高い山は、日本国内ではありません。
入力: quit2つ目の入力では、日本で一番高い山を聞いたつもりなのに、CALM2は「エベレスト」と答えています。
このように、これまでの会話をプロンプトに含めないと、これまでの会話の内容に沿った回答が得られないことが確認できました。
LLMに慣れている人は知っていますが、当たり前すぎて説明されていないことがあります。LLMモデルの初心者🔰の方は注意しましょう。
以下が、これまでの会話をプロントに含めるように修正したチャットプログラムです。
promptにアシスタントの回答を追加し、最後に<|endoftext|>を加えました(これは、公式のテンプレート通り)。
この実装方法で多分あっていると思いますが、もっと良い実装方法がある場合はコメントで教えてください。
また、プログラムに出力を加えて、promptの内容を以下の形式で出力するようにしました(これで、入力されるプロンプトを確認することができます)。
--------------------------------------------------------------------------------
<入力したプロンプトの内容>
--------------------------------------------------------------------------------プログラムは以下になります。コード的には、promptの更新部分が違うだけです。
prompt = ""
while True :
txt = input("入力: ")
if txt == "quit" : break
prompt += f"USER:{txt}\nASSISTANT:"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
print("-"*80)
print(prompt)
print("-"*80)
print("アシスタント:", end=" ")
with torch.no_grad():
tokens = model.generate(
input_ids = input_ids.to(model.device),
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k = 50,
streamer=streamer,
)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
prompt += output.split("ASSISTANT:")[-1] + "<|endoftext|>\n"以下が結果になります。分かりやすいように、promptの内容の部分は水色にしています。
入力: これから日本について質問します。よろしいですか?
--------------------------------------------------------------------------------
USER:これから日本について質問します。よろしいですか?
ASSISTANT:
--------------------------------------------------------------------------------
アシスタント: はい、どうぞ。
入力: 一番高い山は?
--------------------------------------------------------------------------------
USER:これから日本について質問します。よろしいですか?
ASSISTANT: はい、どうぞ。<|endoftext|>
USER:一番高い山は?
ASSISTANT:
--------------------------------------------------------------------------------
アシスタント: 一番高い山は富士山です。
入力: 二番目に高い山は?
--------------------------------------------------------------------------------
USER:これから日本について質問します。よろしいですか?
ASSISTANT: はい、どうぞ。<|endoftext|>
USER:一番高い山は?
ASSISTANT: 一番高い山は富士山です。<|endoftext|>
USER:二番目に高い山は?
ASSISTANT:
--------------------------------------------------------------------------------
アシスタント: 二番目に高い山は妙高山です。
入力: quitこの例では、二回目の入力の「一番高い山は?」に対して、日本で一番高い山と解釈して「富士山」回答しています。このように、プロンプトにこれまでの会話を追加することで、うまく会話を続けることができました。
なお、CALM2の入力は最大32,000トークンなので、32,000を超えるような場合は、過去の部分を削除して32,000トークン以内に収めるような処理が必要になると思います。
トークン化に関してですが、制御文字「ASSISTANT:」が1つのトークンではなく、以下のように4トークンに変換されたのはちょっと驚きでした。
ASS | IST | ANT | : この手の指示は1つになるかと思っていました。
チャットプログラムを組んで感じたのは、「予想以上にハイパーパラメータの影響を受ける」ということです。
今回はtop_kとtempatureを設定していますが、設定によっては変な回答が出力されてしまいます(同じ単語を延々繰り返すなど)。
他にもtop_pやno_repeat_ngram_sizeなど調整できるパラメータは多数ありますが、どのようにすれば良い結果が得られるのかわからないので調整が大変そうだと実感しました。
CALM2を使ってLLMに関して少しだけ深掘りしてみました。自身のコードで使うのはLLMって簡単そうで難しいですどう実装するのが正解なのか、まだ、よくわかっていないからというのもありますが、今後も試行錯誤しながら試してみたいと思います。



