
ESPnet2を使った日本語音声認識(Speech To Text)の手順解説
Aru
Aru's テクログ(Aruaru0)

LangChainを使用してRAG(Retrieval-Augmented Generation)を実装する方法を、CALM2、FAISS、RetrievalQA使った具体例を通じて解説します。大規模言語モデルを動かすのは難しく感じるかもしれませんが、環境さえ構築できればローカル環境で動かすのはそれほど難しくありません。この記事では、LangChainを使ってCALM2を使ったRAGに挑戦しています。参考になれば幸いです。

LangChain(ラングチェイン)は、大規模言語モデル(LLM)を使うためのフレームワークです。LangChainを使えば、LLMを利用した自作アプリケーションを比較的簡単につくることが可能です。
私は、全然LangChainに慣れていないので、「フレームワークを使った方が楽」という感じはまだしていませんが、Webフレームワークなどと同様に慣れればとても便利なものだと思います。
慣れるまでは、LLMを使うための便利関数をたくさん集めたライブラリと思って、必要な機能だけ使えば良いと感じています。
そこで、今回は、LangChainの機能を使ったRAGにチャレンジしてみました。この記事では、RAGの使い方について、実際に動作するコードを交えて解説します。
Retrieval-Augmented Generation (RAG) は、大規模言語モデル(LLM)によるテキスト生成に、外部情報の検索を組み合わせることで、回答精度を向上させる技術のことです。
RAGのイメージは以下の図のようになります。ユーザの質問から外部情報を検索して、質問に関連する情報を取り出します。これを質問と合わせてプロンプトに埋め込み大規模言語モデルに投げることで、質問に関連した回答を得られやすくなります。
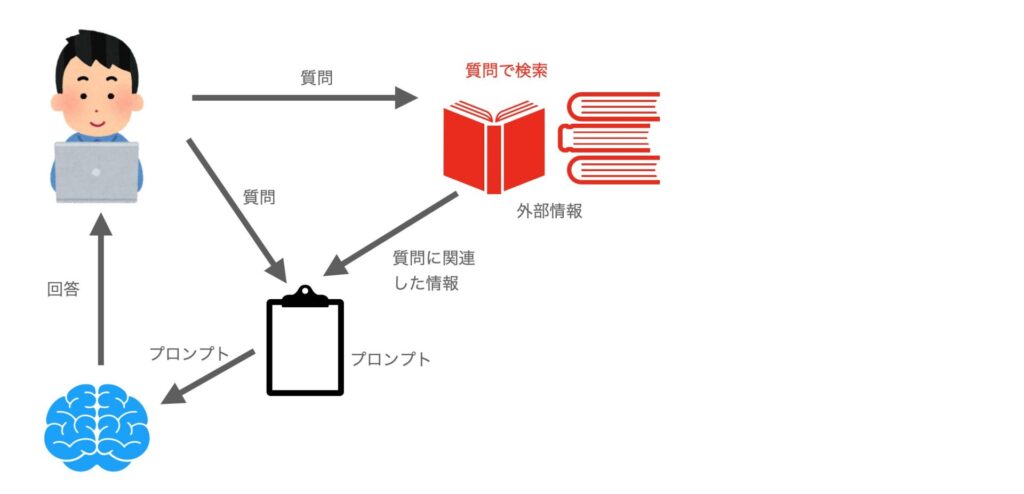
これを実現するには、質問で検索する仕組みと、大規模言語モデルが必要です。今回は、データベースの検索にFaiss, 大規模言語モデルとしてはCALM2を利用します。
この記事で作成するのは、LangChainを使った以下のようなプログラムです。

今回は、wikipediaのページ情報を使ったRAGにチャレンジします

wikipediaの情報は、LLMのモデルの学習で使っていると思うので、RAGがなくても答えられる情報だと思いますが、それでも回答に変化はありました。
Google Colabで実行する場合は、以下のコードを最初に実行し、パッケージのインストールを行ってください。
なお、GPUのメモリが必要となるため、A100などGPUのメモリが多いものを使わないとメモリが不足しますので注意してください(FAISSの部分の文字数を5,000文字から減らせばT4でも動作すると思います)。
!pip install -q accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7
!pip install langchain sentence_transformers
!pip install faiss-gpu RAGを試すには、「外部情報」が必要です。
今回は、手軽に入手できる文章としてwikipediaの情報を利用します。
get_wikipedia_page(keyword)関数は、keywordに関連するページを検索し、そのページの情報をテキスト文書として返す関数です。
今回は、この関数を使ってワンパンマンのwikiページを取得しています。
import requests
def get_wikipedia_page(keyword):
url = "https://ja.wikipedia.org/w/api.php"
params = {
"action": "query",
"list":"search",
"srsearch": keyword,
"srlimit":1,
# "srnamespace": 1,
"format": "json",
}
response = requests.get(url, params=params)
data = response.json()
id = data['query']['search'][0]['pageid']
params = {
"action": "query",
"format": "json",
"pageids": id,
"prop": "extracts",
"exlimit": 1,
"explaintext": True,
"redirects": 1,
}
response = requests.get(url, params=params)
data = response.json()
page = next(iter(data['query']['pages'].values()))
return page.get("extract", "")
wiki_txt = get_wikipedia_page("ワンパンマン")
len(wiki_txt), wiki_txt[:1000]大規模言語モデルを読み込みます。
今回は、CyberAgentのcyberagent/calm2-7b-chatを利用します。
このモデルを利用している理由は「最近、使っているから」です。huggingfaceにある他のモデルでも同様なことが可能だと思いますので、他のモデルに入れ替えて実行することも可能です。
モデルを入れ替えた場合は、プロンプトのテンプレートをモデルに合わせて修正する必要があります。それぞれのモデルが、どのようなフォーマットを要求しているかは、各モデルのドキュメントを調べてください。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model = AutoModelForCausalLM.from_pretrained("cyberagent/calm2-7b-chat",
device_map="auto",
torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("cyberagent/calm2-7b-chat")
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
model.eval()Faiss(Facebook AI Similarity Search)は、類似したドキュメントを検索するためのMetaが作成したオープンソースのライブラリです。これを使うことで、類似したテキストを検索することができます。
ここでは、wikipediaからダウンロードしたテキストを5,000文字単位(オーバラップ500文字)で分割しています(RecursiveCharacterTextSplitter)。
CALM2は32,000トークンまで入力できるので大きめに区切っていますが、他のLLMを使う場合はそれぞれに合わせて調整してください。
その後、FAISSを使ってインデックスを作成しています
これで、近似最近傍探索を行うことができます。
index.similarity_search(txt)で、txtに近いドキュメントを登録した文書(ブロック)から検索できます。
from langchain.chains import RetrievalQA
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.faiss import FAISS
# CALM2は32000トークンまで対応しているので、5000文字と少し大きめのサイズで区切っている
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=5000,
chunk_overlap=500,
)
texts = text_splitter.split_text(wiki_txt)
embedding=HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")
index = FAISS.from_texts(
texts=texts,
embedding=embedding
)
index.save_local("storage")
txt = "ワンパンマンとはなんですか?"
docs = index.similarity_search(txt)以下は、LangChainを使わずに自作のプログラムでRAGを行う例です。
calm2-7b-chatでは、"USER: <ユーザー文書> ASSISAANT:"という入力形式になっているので、このフォーマットでプロンプトを作成しています。
CALM2に関しては以下の記事を参照してください

プロンプトができたら、model.generate()で文章を生成しています。
なお、ここでは、similarity_searchで見つけた1つめの文書だけ埋め込みしています。
txt = "アクエリオンのあらすじを教えてください"
docs = index.similarity_search(txt)[0]
prompt = f"""USER: あなたは以下の情報に詳しいアシスタントです。わかりやすい日本語で答えてください。
以下の情報が質問に関連していない場合は、情報を利用せずに質問に答えてください。
情報:
{docs.page_content}
質問: {txt}
ASSISTANT:"""
input_ids = tokenizer.encode(prompt, return_tensors="pt")
print(f"\n文字数={len(prompt)}, トークン数={len(input_ids[0])}")
print("アシスタント:", end=" ")
with torch.no_grad():
tokens = model.generate(
input_ids = input_ids.to(model.device),
max_new_tokens=1000,
do_sample=True,
temperature=0.7,
top_k = 50,
streamer=streamer,
)結果は、以下になります。ワンパンマンのwikiページをインデックスしているので、別のアニメ(アクエリオン)のあらすじは与えていません。
ただ、LLMを学習データには含まれていたようで、一部正解まじりの回答が出力されました。
あらすじは、ほぼLLMの創作ですが、キーワードにはそれっぽいものが含まれているのが面白いです。
文字数=5118, トークン数=2814
アシスタント: アクエリオンは、全26話の日本のアニメ作品です。2005年4月から6月まで毎日放送と、同年10月から12月まで独立UHF局(テレビ神奈川、テレビ埼玉、千葉テレビ、三重テレビ、岐阜放送、サンテレビ、KBS京都)で放映されました。
物語は、地球と異星人「ディーバ」との戦争から始まります。主人公の少年・ショウは、異星人が地球に送り込んだ「アクエリア」というロボットのパイロットに選ばれ、ディーバとの戦争に身を投じます。
アクエリアは、異星人の技術で作られた巨大ロボットで、エネルギーとして「シャインスパーク」という特殊能力を使うことができます。ショウはアクエリアのパイロットとして、ディーバとの戦闘で活躍しますが、その中で「シャインスパーク」の秘密を知る人物、ユノと交流を持ちます。
ユノは、ディーバの王女であり、彼女が持つ特殊な力「エレメント能力」により、ディーバと地球との共存を模索していました。しかし、ディーバが地球に送り込んだ侵略用ロボット「アクエリオン」の侵攻により、ユノはディーバの王位継承権を放棄し、地球を守る戦いを決意します。
アクエリオンは、ディーバが開発した地球侵略用ロボットであり、強力なエネルギー「ロゴス」を持つ人間を求めます。ディーバはその人間を選び出すため、「エレメント能力」を持つ人間を地球に送り込み、ショウと接触させます。
ショウは、ユノと出会い、アクエリオンのパイロットとして共に戦うことを決意します。アクエリオンは、ロゴスを持つ人間と合体することが可能で、ショウはユノと2機目のアクエリオン「アクエリオンスパーダ」で戦います。
アクエリオンスパーダは、ロゴスにより飛行能力を得ることができ、地上、空中、宇宙空間と、あらゆる場所で戦うことが可能となります。また、アクエリオンスパーダには、武器として「アルテア剣」という特殊剣が搭載され、ロゴスを吸収して攻撃力を高めることができます。
最終的に、アクエリオンスパーダはロゴスを使い果たし、ディーバの女王・ミコノと融合して、ディーバの女王として地球を守ることを宣言します。今回は、ちょっとやらしい質問(RAGとして与えてない情報に関する質問)を行っています。本来の使い方ではないですが、面白そうなので確認してみました。
RAGの目的は「特定ジャンルの質問への強化」だと思うので、この例はあまりよくないかもしれません。
次に、LangChainを使ってRAGを実装してみます。
まず、transformersのpipelineで、tokenizerとmodel、パラメータを登録しパイプラインを作成します。
from langchain.llms import HuggingFacePipeline
from langchain.prompts import PromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema import StrOutputParser
from langchain import PromptTemplate
from transformers import pipeline
pipe = pipeline(
'text-generation',
model=model,
tokenizer=tokenizer,
max_new_tokens=1000,
do_sample=True,
temperature=0.7,
top_k = 50,
)
local_llm = HuggingFacePipeline(pipeline=pipe)このパイプラインをRetrievalQA.from_chain_typeのllmに渡します。
プロンプトはtamplateを作成して、これをPromptTemplate.from_templateに渡し、RetrievalQAに渡します。
これで準備完了です。
あとは、qa_chain.invokeに質問を渡してchainを実行します。
base_template = """USER: あなたは以下の情報に詳しいアシスタントです。わかりやすい日本語で答えてください。
以下の情報が質問に関連していない場合は、情報を利用せずに質問に答えてください。
情報:
{context}
質問: {question}
ASSISTANT:"""
prompt = PromptTemplate.from_template(base_template)
qa_chain = RetrievalQA.from_chain_type(
llm=local_llm,
chain_type="stuff",
chain_type_kwargs={"prompt": prompt},
retriever=index.as_retriever(search_kwargs={"k": 2}),
verbose=True,
)
res = qa_chain.invoke('アクエリオンのアニメシリーズはいくつありますか?')
print(res['result'])相変わらず、外部情報として与えていない内容の質問です。結果は、一部は正解で、一部は間違ったものでした。渡した情報は使われていないっぽいので、プロンプトがうまく動作している(?)のかもしれません。
アクエリオンのアニメシリーズは「アクエリオンEVOL」と「アクエリオン1980」の2つです。res = qa_chain.invoke('ワンパンマンの敵のランクを教えてください')
print(res['result'])次は、与えた外部情報に含まれる内容に関する質問になります。かなりいい感じで回答しています。とりあえずRAGがうまく機能しているようです。
ワンパンマンに登場する怪人のランクは、災害レベルによって表現されます。
災害レベルは、人間が脅威と感じる程度によってランク付けされており、数字が大きくなるほど大きな被害が発生します。
以下に、ワンパンマンの敵のランクを、災害レベルによって示します。
* 災害レベル「竜」:怪人の中でも特に強い存在で、人間であればほとんど死亡する。
* 災害レベル「鬼」:怪人によって人間が大量殺害されるレベル。
* 災害レベル「虎」:怪人によって人間が負傷し、住処を追われるレベル。
* 災害レベル「竜」程度の強さを持つ怪人:竜に匹敵する脅威を持つが、まだ対処可能なレベル。
* 災害レベル「鬼」程度の強さを持つ怪人:鬼に匹敵する脅威を持つが、対処可能な範囲内であるレベル。
* 災害レベル「虎」程度の強さを持つ怪人:虎に匹敵する脅威を持つが、対処可能な範囲内であるレベル。
* 災害レベル「竜」未満の怪人:脅威度は低いが、対処が必要なレベル。res = qa_chain.invoke('無限パンチとはなんですか?')
print(res['result'])次は、微妙な質問です。「無限パンチ」というパンチはワンパンマンにありませんが、パンチという言葉はたくさん出てきます。本来「無限パンチ」はアクエリオンの必殺技ですが、ワンパンマンを外部情報で与えているので、ワンパンマンの技名として回答しました。
若干間違っていますが、この質問に対して外部情報に従って回答していることがわかります。
無限パンチとは、漫画「ワンパンマン」に登場する技の名前です。以上、LangChain、CALM2, Faissを使ってRAGにチャレンジしてみました。比較的簡単に作成できますが、プロンプトの工夫など色々チューニングする余地はありそうです。
また、CALM2は32,000トークンまで入力できるので、もう少し長い外部情報を与えて精度をあげることも可能な気がします。
とりあえず、RAGを行うコードを作ってみましたが、実際には、FAISSの辞書の作り方や、プロンプトの作り方など、いくらでも改善する部分がありそうな気がしました。
差別化する部分は無いと思っていましたが、いろいろできそうです



