Santa 2023 : The Polytope Permutation Puzzleに挑戦| Kaggleチャレンジ記録
Aru
Aru's テクログ(Aruaru0)

Kaggleのコンテストの「CommonLit – Evaluate Student Summaries」へチャレンジした記録です。私が行った取り組みを時系列でまとめています。結果は、2106グループ中83位の銀メダルでした。
CommonLit – Evaluate Student Summariesは、Kaggleで開催されたコンペです。
このコンテストの目的は、「3 年生から 12 年生までの生徒が書いた要約の質を評価すること」です。
今回はこのコンテストに参加し、2106グループ中83位で、銀メダルを獲得できました。


この記事は、私がKaggleのコンテストに参加したときの記録になります。特に優れた成績を収めたわけではありませんが、これからKaggleに参加しようと考えている方の参考になればと思い、記録を残します。
なお、今回の記事のコードは以下にあります。整理されていないので読みにくいかと思いますが参考になれば幸いです。
Kaggle Notebook
学習用コード(GitHub)はこちら
今回は、少し遅れて締め切りの1ヶ月前から参加しました。参加自体はもう少し早いタイミングに決めていたのですが、別の用事で結局1ヶ月前になりました。
自前のコードを書きたかったのですが、1ヶ月でキャッチアップして、改良を行う必要があったので、今回は公開されているコードをベースに修正していくアプローチを取りました。
まずは、概要(Overview)を読んでコンテストの趣旨を理解することから開始。大体の内容がわかった時点で、今回は言語モデルを使った機械学習だとあたりをつけ、transformerについて調査開始(調べたことは一応記事にして次回活用できるようにしています)。

今回は、回帰問題になりそうなのでそちらもキャッチアップ。

いつものようにEDA(Explanatory Data Analysis=探索的データ分析)と、参加時点でPublic Scoreの高いコードのチェックを行いました。
予想通り、BERT系を使ったソリューションが上位に来ているようでした。また、使い方は、事前に記事にした内容とほぼ同じことも確認。
公開コードをそのまま実行すると処理時間がかかるので、学習部分と推論部分を、2つのノートブックに分割しました。これで、学習と、提出のための推論を個別に行うことができます。
分離して提出するコードを軽くしておけば、複数モデルのアンサンブルが可能になります。
とりあえず、公開コードのパラメータを振っていくつか学習をやってみました。CVを見ても効果がなさそうな雰囲気。とりあえず、一番CVが高いものをサブしてみるとLB0.455(522位)。ここから改良を加えて順位をあげていくことになります。
公開コードがdeverta-v3-baseを使っていたので、これをbert, robertaなどに変更して学習させてみました。結果は効果なし、というか悪化。色々試したかったですが、とりあえずはdeverta-v3で進めることにします。
deverta-v3-baseをdeverta-v3-largeに変更して学習にチャレンジしました。Kaggleノートブックでは、メモリ不足のエラーが解消できないまま、週のGPU(30時間)を使い切りました。
ここで、Google Colab Pro+を契約。学習環境をColab Pro+に移行させました。最初は、kaggleとColabの両方で実行可能なようにコードを作ってましたが、Largeモデルの学習結果を保存させるにはKaggleの実行環境ではディスク容量が足りないことがわかり、両方で実行できるコード挿入は中途半端な状態で放置。
ちなみに、LargeモデルをGPUメモリが不足する環境学習させる場合には、バッチサイズを小さくする必要があります。HuggingFaceのTrainerはよくできていて、バッチサイズが大きくできないときは、Gradient Accumulationという手法を使うのですが、オプションで指定することができます。具体的には、以下のようにTrainerArgumentsで設定します。
batch_sizeはメモリにギリギリ収まる3に設定したので、$3 \times 4 = 12$で、バッチサイズ12相当の動きになります(厳密には少し異なります)。
training_args = TrainingArguments(
per_device_train_batch_size=batch_size,
gradient_accumulation_steps = 4,
)Gradient Accumulationを使えば、GPUメモリが少なくてもバッチサイズを大きくすることができるので覚えておいて損はないと思います。HuggingFaceのTrainer、結構多機能です。また、メモリ節約のためにfp16のオプションをつけて、Largeモデルの学習ができるようにしました。
training_args = TrainingArguments(
per_device_train_batch_size=batch_size,
fp16=True,
gradient_accumulation_steps = 4,
)deverta-v3-baseをdeverta-v3-largeに変更したモデルを使ったバージョンをサブしたところ、順位が77位(LB0.441)とメダル圏内にスコアが上昇しました。
ここから、GPU時間が気になったので、deverta-v3-baseモデルで学習→評価し、結果が良かったものだけlargeモデルで学習する作戦を取りました。
以下、トライしたものです。
この結果を受けて、largeモデルで、スペルミス数を埋め込んだモデルと、スペルミス修正前で学習したモデルと最初に学習させたモデルの3つのアンサンブルを行ってみたところ、スコアがLB0.441→LB0.44とアップ。
さらに、largeモデルとbaseモデルのアンサンブルを行いしましたが、こちらはスコアが上がらない感じでした。largeモデルとbaseモデルの単体スコアの開きが結構あるので、アンサンブルしてもスコアがあがるより下がるといった感じみたいでした。
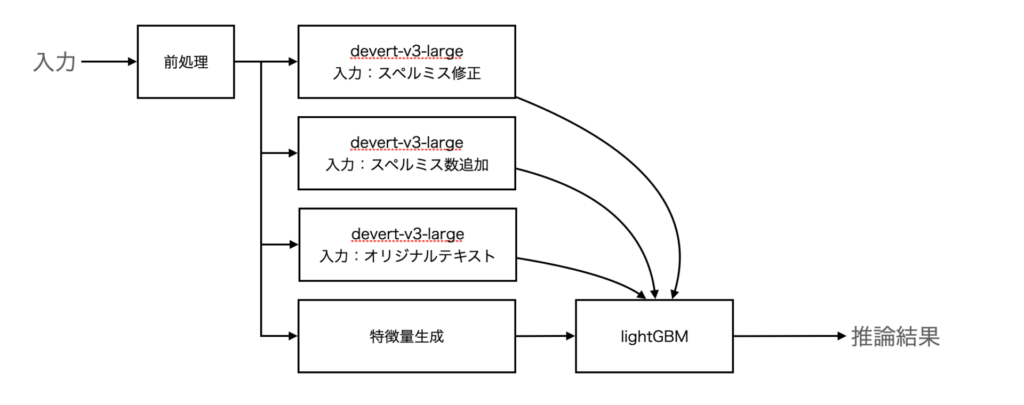
参考にしたコードでは、deverta-v3-baseで推論した結果と文書から抽出した特徴量を用いて、lightGBMによる推論が行われていました。transformerの部分の改善に煮詰まったので、こちらの部分の検討を行いました。
LightGBMをCatBoost変更してみました。baseモデルではCV/LBともにアップしましたが、largeモデルではCV/LB共にダウンしました。そこまで効果がなさそうなとでCatBoostはとりあえず保留にしました。
特徴量の見直しを行いました。テキストの特徴量を取り出すライブラリpy_readability_metricsとtextstatを利用。また、コサイン類似度の計算を追加しました。

この変更で、LB0.437にスコアアップ
この時点でのモデルの構造はこんな感じです。
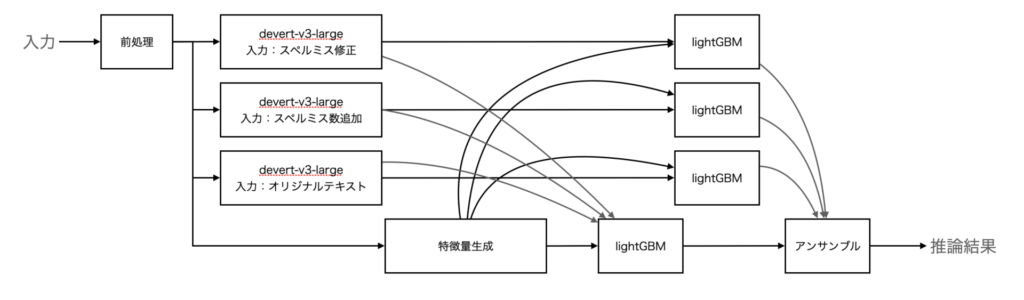
ここで知人とチームを組みました。スコア的に、私の方が結構高かったので私の書いたコードをベースに検討開始。下記のように、個別のdevertaの結果に対してもlightGBMで推論結果を出し、4つをアンサンブルすることでLB0.434にスコアアップしました。
1人で考えるより、複数で考えた方がアイデアがでるものです。
この後、パラメータ調整・特徴量追加などしましたが、それほど上がらず
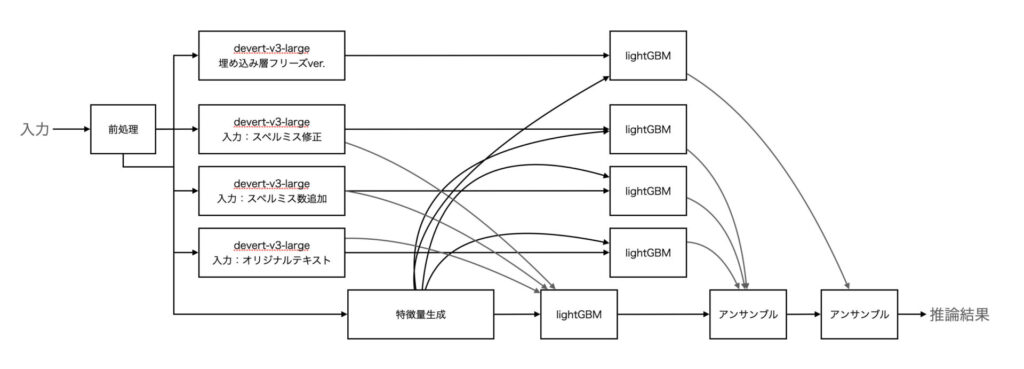
ギリギリですが、devertaの学習の見直しを行いました。もともと考えていたのですがやっていなかった、埋め込みレイヤー付近のフリーズにチャレンジです。今回は、7層フリーズしました。

これがかなり効果があって、deverta-v3-largeの単体モデルでLB0.433に!
いくつか学習パラメータを変えて学習させてみましたが、最初に学習させたやつ以外はイマイチでした。また、フリーズして学習したモデルを組み合わせたものもイマイチ。
この時点で締め切りまで残り2日だったので、スコアの高かった単体を残してあとは使わないことにしました。
ふと、LB0.434のモデルとLB0.433のモデルをアンサンブルしたら結果はどうなるか気になったので、アンサンブルしてみました。結果はLB0.431とスコアアップ。この時点で46位とかなりよいポジションに入ることができました。
最終のアンサンブル以下になります。
提出候補の選択は悩みましたが、いつものようにLBベスト、CVベストと今回は3つ目も提出できたので最後に検討したモデルとしました。
結果はLBから37ダウンの83位で、銀メダルでした。銀メダルになんとか残れたので良かったです。ただ、提出したモデルは、ベストではありませんでした。というか、自身の作成したモデルの16番目の成績のモデルでした。
一番スコアが良かったのは、パラメータの一部をフリーズしたdeverta-v3-largeの単体モデルでした。LBはデータの一部なのでこの選択が非常に難しいです。
ベストスコアと提出した3つのうちのベストスコアは以下の通りでした。今回のベストはCVベストでもLBベストでもないモデルでしたので、最終提出に選択しませんでした。流石に、これを提出する判断は難しいです(最終サブ候補として頭には浮かんだのですが結局選択しませんでした)。
| Private Score | Public Score | |
| ベストスコア | 0.469 | 0.433 |
| 提出したベスト | 0.474 | 0.431 |
以下が、取り組みによるPublic Scoreの変化です。
| 取り組み内容 | Public Score |
| 最初のサブ | 0.455 |
| deverta-v3-baseからdeverta-v3-largeへ変更 | 0.441 |
| アンサンブル(3モデル) | 0.44 |
| lightGBMの特徴量の見直し | 0.437 |
| アンサンブルを見直し | 0.434 |
| 埋め込み層から7層をフリーズしたdeverta-v3-largeを学習(単体) | 0.433 |
| 0.434のモデルと0.433のモデルのアンサンブル | 0.431 |
以上、commonlitの取り組みについて説明しました。今回は締切1ヶ月前から参加したため、それほど工夫をすることができませんでした。特に、Google Colab ProのT4だと、devert-v3-largeの学習に半日以上かかるので、実験をそれほど回すことができませんでした。
kaggle参加時にどのような取り組みをしているのかの参考になれば幸いです。
コンテスト終了後に、上位の手法がDiscussionで公開されます。これを見るとスキルがアップすると思います。つぎの文章系のコンペでは、上位手法を参考にしていこうと思います。

5位のソリューションは、似たトライをやっていますが、結果は全然違います。この差が埋まらないです。